what's parse tree
剖析樹(parse tree)
- 根據一語言的文法(BNF;Backus–Naur form)描述,將此語言某一語句(statement)之語法結構,以階層式樹狀結構來表示。


- y=f(x),x是某語言的語句(statement),Y是剖析樹,f(T)函數是BNF 文法
- 每一步推論最左(右)邊的非終端節點 left(right)-most derivation sequence
不明確文法(ambiguous grammar)
- 語言某一語句(statement),依文法推導可得到兩顆或以上的剖析樹,稱該文法模糊
文法定義
一個文法G可以定義為G=(Vn,Vt,S,P)
- Vn 非終端節點的集合 (nonterminal symbol),如{<assign>,<expr>,<id>}
- Vt終端節點的集合 (terminal symbol),如{A,B,C}
- S 開始符號集合(starting symbol),如{<assign>}
- P 產生規則集合(production rule)
考題
一、根據下列文法,其中非終端(non-terminal)以< >符號標示:
<S> → <A>
<A> → <A> + <A> | <ID>
<ID> → w | x | y | z
請畫出 x+y+x 所對應之剖析樹(parse tree)。(10 分)
請問此文法是否模糊(ambiguous)?請說明。(10 分
答案


下面為chatgpt的回答
下面是字符串"x+y+x"所对应的解析树(parse tree):
```
<S>
|
<A>
|
<A>
/|\
x + <A>
|
<A>
|
<ID>
|
x
```
在这个解析树中,<S>(开始符号)扩展为<A>,然后再扩展为<A> + <A>,依此类推,直到达到终端符号<ID>为止。
、考慮下列文法: SÆ(L)| a LÆL,S | a
(一)請指出此文法的 terminal symbol, non-terminal symbol, and start symbol.(6 分)
(二)請為(a, (a, a))字串,根據上述文法,做出 left-most derivation sequence.(4 分)
(三)請為(a, (a, (a, a)))字串,根據上述文法,做出 right-most derivation sequence.(4 分
我的答案
(一)
terminal symbal:{a,(,)}
non-terminal symbal:{L,S}
start symtol:S
(二) 每一步推論最左邊的非終端節點 left-most derivation sequence
S=>(L)=>(L,S)=>(a,(L))=>(a,(L,S))=>(a,(a,a))
(三)
S=>(L)=>(L,S)=>(L,(L,S))=>(L,(L,(L,S)))=>(L,(L,(a,a)))=>(L,(a,(a,a)))=>(a,(a,(a,a)))
下面為chatgpt答案
以下是對每個小題的答案:
(一) 此文法的 terminal symbol 是 {a, (, )},non-terminal symbol 是 {S, L},而 start symbol 是 S。
(二) (a, (a, a)) 字串的 left-most derivation sequence 如下:
S => aL => (aS => (aL,S => (aS) => (aL,S) => (a,a) => (a, a) => (a, (a, a))
(三) (a, (a, (a, a))) 字串的 right-most derivation sequence 如下:
S => aL => a(L,S => a(L,S) => a(L, S) => a(L, (aS) => a(L, (aL,S => a(L, (aL, S) => a(L, (a, S) => a(L, (a, (aS) => a(L, (a, (a, S) => a(L, (a, (aL,S => a(L, (a, (aL,S => a(L, (a, (aS) => a(L, (a, (a, a))))
請注意,這些導出過程可能有多種不同的排列組合。
这个文法不是模糊(ambiguous)的,因为对于给定的输入字符串,只有一种解析树与之对应。在这个文法中,每个<A>都只能扩展为一个<A> + <A>或一个<ID>,不存在多义性或多个可能的解析方式。
給定下列的語法(grammar) SÆ aAb |bBA AÆab|aAB BÆaB|b,
請畫出下列各字串所對應的分析樹(parse tree):(每小題 5 分,共 15 分)
(一)aaAbb
(二)baaBaaABab
(三)aaaAaBaBb
我的答案



chatgpt的回答
以下是對每個字串的分析樹:
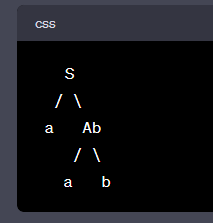
(一) 分析樹 for "aaAbb":
```
S
/ \
a Ab
/ \
a b
```
(二) 分析樹 for "baaBaaABab":
```
S
/ \
b A
/ \
a B
/ \
a A
/ \
A b
/ \
a B
/ \
a b
```

(三) 分析樹 for "aaaAaBaBb":
```
S
/ \
a A
/ \
a B
/ \
a B
/ \
a B
/ \
a b
```

這些分析樹代表了每個輸入字串的語法結構。
以下的語法是 ambiguous
string → string + string | string – string | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 這個文法針對 9-5+2 可以產生兩個剖析樹(parsing tree),請畫出這兩個剖析樹。 (10 分) 為了糾正這樣的問題,請將上述的語法改寫成左結合(Left Associativity)來產生 單一的剖析樹。以 9-5+2 為例,你的左結合語法所產生的剖析樹,將可以單一的 解釋 9-5+2 為((9-5)+2)。(15 分我的回答

(二)參考chatgpt 回答
Comments
Post a Comment